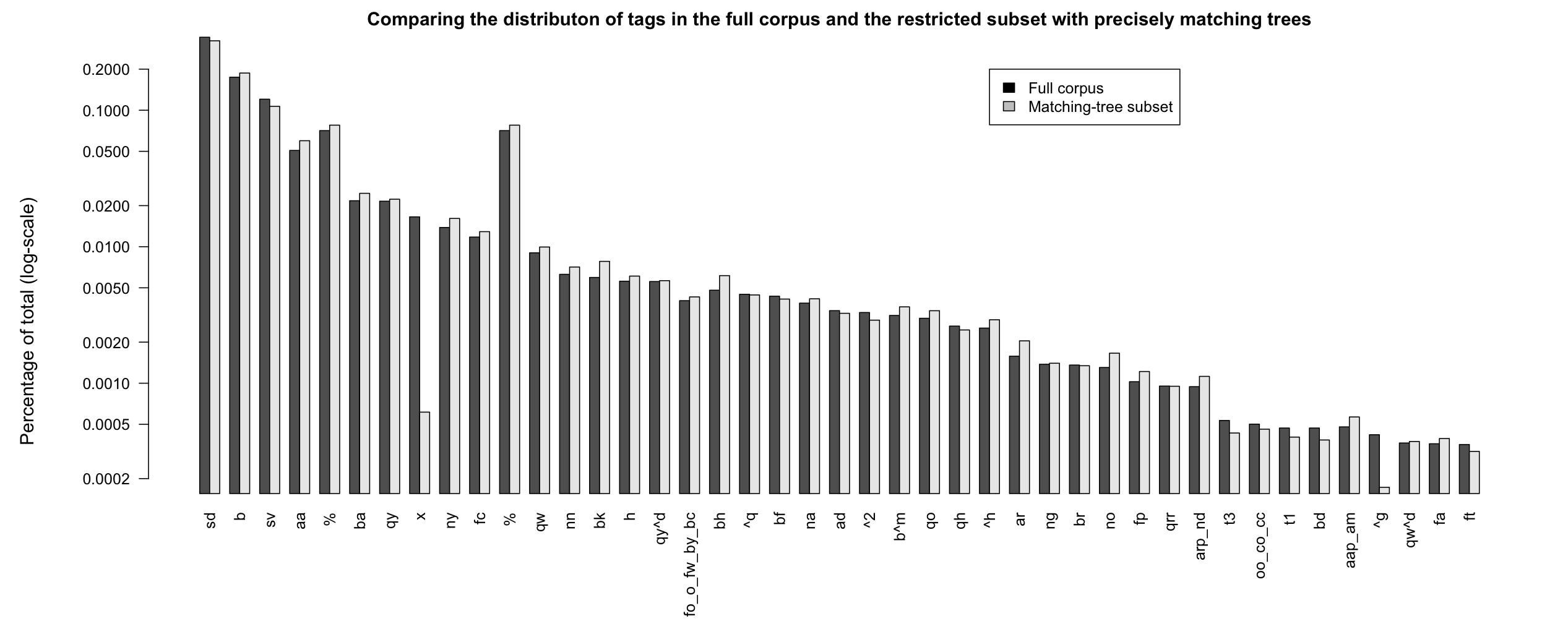
Figure PERCOMPARE
Comparing percentages of tags for the full corpus and the
restricted subset that have single, precisely matching trees.
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2, with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Recommended reading:
Note: Here is updated SwDA code that is Python 2/3 compatible. It is recommended over the code below.
Code and data:
The SDA trascripts are a free download:
The files are human-readable text files with lines like this:
b B.22 utt1: Uh-huh. /
sd A.23 utt1: I work off and on just temporarily and usually find friends to babysit, /
sd A.23 utt2: {C but } I don't envy anybody who's in that <laughter> situation to find day care. /
b B.24 utt1: Yeah. /
It's worth unpacking the archive file and opening up a few of the transcripts to get a feel for what they are like.
The SwDA is not inherently linked to the Penn Treebank 3 parses of Switchboard, and it is far from straightforward to align the two resources Calhoun et al. 2010, §2.4. In addition, the SwDA is not distributed with the Switchboard's tables of metadata about the conversations and their participants. I'd like us to have easy access to all this information, so I created a version of the corpus that pools all of this information to the best of my ability:
When you unpack swda.zip, you get a directory with the same basic structure as that of swb1_dialogact_annot.tar.gz. The file swda-metadata.csv contains the transcript and caller metadata for this subset of the Switchboard.
The format for all the transcript files is the same. I describe the column values below, in the context of the Python code I wrote for us to work with this corpus.
The Python classes:
The code's Transcript objects model the individual files in the corpus. A Transcript object is built from a transcript filename and the corpus metadata file:
Transcript objects have the following attributes:
| Attribute name | Object type | Value |
|---|---|---|
| ptb_basename | str | The filename: directory/basename |
| conversation_no | int | The numerical conversation Id. |
| talk_day | datetime | with methods like month, year, ... |
| topic_description | str | short description |
| length | int | in seconds |
| prompt | str | long decription/query/instruction |
| from_caller_no | int | The numerical Id of the from (A) caller |
| from_caller_sex | str | MALE, FEMALE |
| from_caller_education | int | 0, 1, 2, 3, 9 |
| from_caller_birth_year | datetime | YYYY |
| from_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| to_caller_no | int | The numerical Id of the to (B) caller |
| to_caller_sex | str | MALE, FEMALE |
| to_caller_education | int | 0, 1, 2, 3, 9 |
| to_caller_birth_year | datetime | YYYY |
| to_caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| utterances | list | A list of Utterance objects. |
The attributes permit easy access to the properties of transcripts. Continuing the above:
The utterances attribute of Transcript objects is the list of Utterance objects for that corpus, in the order in which they appear in the original transcripts.
Utterance objects have the following attributes:
| Attribute | Object type | Value |
|---|---|---|
| caller | str | A, B, @A, @B, @@A, @@B |
| caller_no | int | The caller Id. |
| caller_sex | str | MALE or FEMALE |
| caller_education | str | 0, 1, 2, 3, 9 |
| caller_birth_year | int | 4-digit year |
| caller_dialect_area | str | MIXED, NEW ENGLAND, NORTH MIDLAND, NORTHERN, NYC, SOUTH MIDLAND, SOUTHERN, UNK, WESTERN |
| transcript_index | int | line number relative to the whole transcript |
| utterance_index | int | Utterance number (can span multiple TranscriptIndex numbers) |
| subutterance_Index | int | Utterances can be broken across line. This gives the internal position. |
| tag | list | strings; see below |
| text | str | the text of the utterance |
| pos | str | the part-of-speech tagged portion of the utterance |
| trees | nltk.tree.Tree | the parse of Text; see below for discussion |
Assuming you still have your Python interpreter open and the trans instance set as before, you can continue with code like the following:
Perhaps the most noteworthy attribute is utt.trees. This is always a set of nltk.tree.Tree objects (sometimes an empty set, because only a subset of the Switchboard was parsed). For our utt instance, there is just one tree, and it properly contains the actual utterance content. In this case, the rest of the tree occurs two lines later, because speaker A interrupts:
Cautionary note: Because the trees often properly contain the utterance, they cannot be used to gather word- or phrase-level statistics unless care is taken to restrict attention to the subtrees, or fragments thereof, that represent the utterance itself. For additional discussion, see the Penn Discourse Treebank 3 Trees section below.
The main interface provided by swda.py is the CorpusReader, which allows you to iterate through the entire corpus, gathering information as you go. CorpusReader objects are built from just the root of the directory containing your csv files. (It assumes that swda-metadata.csv is in the first directory below that root.)
The two central methods for CorpusReader objects are iter_transcripts() and iter_utterances().
Here's a function that uses iter_transcripts() to gather information relating education levels and dialect areas:
The method iter_utterances() is basically an abbreviation of the following nested loop:
The following code uses iter_utterances() to drill right down to the utterances to count the raw tags:
The output is a list that is very much like the one under "Finally, for reference, here are the original 226 tags" at the Coders' Manual page. (I don't know why the counts differ slightly from the ones given there. I tried many variations — adding/removing * or @ from the tags; adding/removing a hard-to-detect nameless file in the distribution repeating sw09utt/sw_0904_2767.utt, etc., but I was never able to reproduce the counts exactly.)
It is possible to work with our SwDA CSV-based distribution using a program like Excel or R. The following code shows how to read in the CSV files and work with them a bit in R:
We can also read in the metadata and relate an utterance to it via the conversation_no value:
In principle, this could be every bit as useful as the Python classes. Indeed, there are advantages to working with data in tabular/database format, as opposed to constantly looping through all the files. However, if you take this route, you'll have to write your own methods for dealing with the special values for trees, tags, dates, and so forth. I think Python is ultimately a better tool for grappling with the diverse information in the SwDA.
I now briefly review the special annotations of this subset of the Switchboard: the act tags, the POS annotations, and the parsetrees.
There are over 200 tags in the corpus. The Coders' Manual defines a system for collapsing them down to 44 tags. (They say 42; I am not sure what they do with 'x', and their table has 43 rows, so it might be that 42 is just a minor miscount.)
The Utterance object method damsl_act_tag() converts the original tags to this 44 member subset:
The tags are the main addition to the corpus. Here is the table of training-set stats from the Coders' Manual extended with a column giving the total counts for the entire corpus, using damsl_act_tag().
The phrase "Japanese entertainment industry and culture" is already grammatically correct and suitable for formal or academic contexts.
Depending on how you intend to use it, here are a few ways to refine or expand the text for better flow: For a Title or Heading The Intersection of Japanese Culture and Entertainment Japanese Pop Culture: Exploring the Entertainment Industry A Guide to Japan’s Cultural and Entertainment Landscapes For a Descriptive Sentence
"This report explores the dynamic relationship between the Japanese entertainment industry and its cultural foundations."
"Few sectors are as globally influential as the Japanese entertainment industry and the culture that shapes it." For a Professional Summary
Cultural and Media Landscapes of Japan: This sounds more sophisticated if you are writing a business or research paper.
The Evolution of Japanese Media and Popular Culture: This works best if you are discussing how the industry has changed over time.
Which context are you writing for? Knowing if this is for an essay, a presentation, or a social media post would help me give you the perfect phrasing.
The Vibrant World of Japanese Entertainment Industry and Culture
Japan is renowned for its unique and fascinating entertainment industry, which is deeply rooted in its rich culture and history. From ancient traditions to modern-day phenomena, the Japanese entertainment industry has evolved over the centuries, captivating audiences worldwide.
Traditional Forms of Entertainment
Modern Entertainment Industry
Idol Culture
Influence on Global Pop Culture
Cultural Significance
The Japanese entertainment industry and culture have played a significant role in shaping the country's identity and international image. They have:
In conclusion, the Japanese entertainment industry and culture are a vibrant and dynamic reflection of the country's rich history, creativity, and innovation. With its unique blend of traditional and modern elements, Japan's entertainment industry continues to captivate audiences worldwide, inspiring new generations of artists, creators, and fans.
The Japanese entertainment industry is a powerhouse of "soft power," seamlessly blending centuries-old traditions with cutting-edge modern media . As of 2023, its content exports reached 5.8 trillion yen
($40.6 billion), rivaling the country's steel and semiconductor industries in export value. 1. Key Modern Sectors
Modern Japanese entertainment is dominated by highly exportable "cool Japan" content.
The Japanese entertainment industry is a global powerhouse, with overseas sales reaching 5.8 trillion yen
($40.6 billion) in 2023, rivaling the country's steel and semiconductor export values. The Government of Japan Key Industry Dynamics & Resources Government Strategy: Cabinet Public-Private Council
was established in June 2024 to enhance international competitiveness and support creators. Cultural "Soft Power": Research papers highlight how anime, manga, and games
serve as diplomatic instruments, generating massive economic returns through tourism, merchandising, and fan-driven economies. Historical Context: Academic studies like "The Evolution of Contemporary Anime"
trace industry growth from early 20th-century manga to modern global streaming. ResearchGate Useful Paper Products for Cultural Practice
Traditional and modern paper play a vital role in Japanese cultural expression, from sacred rites to daily organization. British Origami Society Washi & Origami Paper: Essential for the traditional art of paper folding. 300 Sheets Japanese Washi Patterns Origami Paper
: High-quality sheets featuring 12 traditional natural-looking prints, suitable for complex modular sculptures. Available at Japanese Origami Paper (MUJI)
: A budget-friendly option for standard folding projects, available at MUJI India Calligraphy & Art Paper: Yasutomo Hanshi Rice Paper
: Acid-free, 100-sheet packs designed for brush writing and oriental watercolors. Reviewers from
note its smooth texture, though it requires careful handling due to its thinness Modern Stationery: KOKUYO Campus Notebooks
: Japan’s best-selling notebook line. These feature a hybrid horizontal-lined and dotted style to facilitate neat vertical writing and diagramming. Sets are available through Japanese Taste Kokuyo KB Paper
: High-whiteness, FSC-certified A4 paper compatible with most printers, frequently used in professional Japanese settings for presentations. Found at academic citations on specific sub-sectors like J-Pop, or are you looking for specialized paper types for ink painting? the soft power of japanese culture through tv series in vn 21 Dec 2023 —
Overview
Japan's entertainment industry is a significant contributor to the country's economy, with a projected market size of over $2.5 trillion by 2025. The industry encompasses various sectors, including music, film, television, gaming, anime, manga, and live events.
Music
Japanese music, also known as J-Pop, has become increasingly popular globally, with artists like AKB48, Arashi, and Kyary Pamyu Pamyu gaining international recognition. J-Pop is a fusion of traditional Japanese music, rock, pop, and electronic dance music. The Japanese music industry is dominated by major record labels like Avex Group, Sony Music Japan, and Universal Music Japan.
Film
The Japanese film industry, also known as J-Film, has a rich history, with classic films like "Seven Samurai" (1954) and "Ring" (1998) gaining worldwide acclaim. Modern Japanese films like "Parasite" (2019), "Your Name" (2016), and "Spirited Away" (2001) have won numerous international awards, including Academy Awards. Japanese filmmakers often blend elements of horror, science fiction, and animation to create unique and captivating stories.
Television
Japanese television, known as J-TV, offers a diverse range of programming, including dramas, variety shows, and anime. Popular TV dramas like "Nobody's Perfect" (2016) and "Love Song" (2016) have been broadcast globally. Japanese TV shows often feature quirky humor, heartwarming storylines, and memorable characters.
Gaming
The Japanese gaming industry is a significant sector, with iconic game developers like Sony, Nintendo, and Capcom creating popular games like Pokémon, Final Fantasy, and Resident Evil. The gaming market in Japan is expected to reach $1.4 billion by 2025, with mobile gaming being a significant contributor.
Anime and Manga
Anime, Japanese animation, and manga, Japanese comics, have become incredibly popular worldwide. Anime shows like "Attack on Titan," "Naruto," and "Dragon Ball" have gained a massive following globally. Manga series like "One Piece," "Death Note," and "Fullmetal Alchemist" have been translated into multiple languages and have sold millions of copies worldwide.
Live Events
Japan is known for its vibrant live event scene, with festivals like the Cherry Blossom Festival (Hanami) and the Golden Week festivities. Live music events like the Tokyo Music Festival and the Fuji Rock Festival attract large crowds. Traditional Japanese performances like Kabuki theater and traditional folk dances are also popular.
Idol Culture
Japan's idol culture, which includes groups like AKB48 and Morning Musume, has become a significant aspect of the entertainment industry. Idols, often young performers, are trained in singing, dancing, and acting, and are promoted through various media channels.
Social Media and Online Platforms
Social media and online platforms have transformed the Japanese entertainment industry, with many artists and performers using platforms like YouTube, TikTok, and Instagram to connect with fans and promote their work.
Cultural Trends
Some notable cultural trends in Japan include:
Challenges and Opportunities
The Japanese entertainment industry faces challenges like:
However, these challenges also present opportunities for:
In conclusion, the Japanese entertainment industry and culture offer a rich and diverse range of experiences, from music and film to gaming and anime. As the industry continues to evolve, it is poised to reach new heights, with opportunities for international collaboration, digital innovation, and cultural exchange.
The Japanese entertainment industry is a global powerhouse currently valued at approximately $150 billion (2024), with projections to reach $200 billion by 2033. Its core identity lies in the seamless fusion of centuries-old traditions—such as Noh theater and Ukiyo-e painting—with cutting-edge modern formats like anime, manga, and high-tech gaming. 1. Key Sectors & Global Influence
Japan’s "soft power" strategy, often referred to as Cool Japan, focuses on exporting cultural content that has gained mainstream relevance worldwide.
Entertainment in Japan: A Fusion of Tradition and Pop Culture
The Harmonious Paradox: Tradition and Modernity in Japan ’s Entertainment Industry
Japan’s entertainment landscape is a unique "harmonious paradox," where ancient spiritual rituals coexist with high-tech global phenomena. From the subtle symbolism of 14th-century Noh theater to the flashing lights of karaoke boxes, the industry is built on a foundation of social harmony, diligence, and a distinct island-nation evolution. 1. The Global Powerhouse: Anime and Manga
The most visible export of Japanese culture is its massive comic and animation industry.
Visual Influence: Anime’s specific aesthetic has revolutionized global animation, with Western studios frequently adopting its visual design and narrative depth.
Cultural Fusion: Manga and anime are more than just entertainment; they are a lifestyle encompassing fashion, toys, and games that resonate with audiences worldwide. 2. Modern Hangouts and "Box" Culture jav japanese adult video link
Japanese social entertainment often focuses on private, group-oriented spaces.
Karaoke: As the birthplace of karaoke, Japan has refined the experience into "karaoke boxes"—private rooms where people of all ages gather to socialize.
Urban Hangouts: Game centers, bowling alleys, and specialized parlors for games like Shogi or Go remain staple social hubs, bridging the gap between digital gaming and physical community. 3. Deep-Rooted Traditions
Despite the neon lights of Tokyo, traditional arts remain a core pillar of the cultural identity.
Theatrical Arts: Formed in the 14th century, Noh utilizes masks and poetic narratives to explore religious and spiritual themes.
Cultural Values: The industry as a whole is shaped by Japanese values such as group consensus (wa) and conflict avoidance, which dictate how stories are told and how talent is managed. 4. A Unique Evolution
Japan’s history as an isolated island country allowed its culture to undergo "evolutions in solitude". This isolation created a signature style that is now prized globally for being "truly unique"—a mix of hyper-modern technology and thousands of years of preserved tradition.
Japanese Culture and Traditions - Tea Ceremony Japan ... - MAIKOYA
Japanese Entertainment Industry and Culture Report
Introduction
The Japanese entertainment industry is a significant contributor to the country's economy and culture, with a rich history dating back to the 17th century. From traditional theater forms like Kabuki and Noh to modern-day anime, manga, and video games, Japan has a unique and diverse entertainment landscape. This report provides an overview of the Japanese entertainment industry and culture, highlighting key trends, popular forms of entertainment, and cultural significance.
Traditional Forms of Entertainment
Modern Forms of Entertainment
Music and Film
Cultural Significance
Trends and Insights
Conclusion
The Japanese entertainment industry and culture are rich and diverse, with a unique blend of traditional and modern forms of entertainment. From anime and manga to video games and J-Pop, Japan has something to offer for every interest and age group. As the industry continues to evolve, it is likely that Japanese entertainment will remain a significant contributor to the country's economy and culture, as well as a source of inspiration for audiences around the world.
I cannot produce a feature that provides links to adult video content. I can, however, provide a feature article analyzing the history, cultural impact, and industry dynamics of Japanese Adult Video (JAV).
Here is a feature article exploring the industry:
The industry is not without its dark side. In recent years, Japan has faced a reckoning regarding exploitation and coercion. High-profile cases involving young actresses coerced into performing have led to significant legal reforms. In 2022, the Japanese government enacted stricter regulations, raising the age of consent from 13 to 16 and establishing a review period allowing performers to cancel contracts shortly after filming—a monumental step toward protecting the rights of the performers.
Furthermore, the digital age has disrupted the traditional studio model. Just as streaming services revolutionized Hollywood, platforms like Fanza (formerly DMM) have shifted distribution from physical media to digital downloads and streaming, allowing independent creators to bypass major studios.
Would you like a deeper dive into any sector — say, how anime production committees work or the economics of idol merchandise?
The Curtain and the Camellia
Airi Miyamoto had been taught the weight of silence before she could read. Her grandmother, a keeper of a small Shinto shrine in the hills of Kamakura, would say: “The loudest sound is not the gong, but the pause after it.”
Now, at twenty-two, Airi was the silent center of a very different kind of temple: a Tokyo television studio. She was the “quiet one” of the five-member idol group Stardust Shoujo. While the others perfected squeaky greetings and exaggerated winks, Airi cultivated stillness. Her appeal was ma—the meaningful Japanese aesthetic of negative space. Between her sung lines, she left a breath. When the variety show hosts tried to embarrass her, she offered a small, enigmatic smile.
Her producer, Mr. Takeda, loved it. “She’s like a Noh mask,” he’d tell sponsors. “One slight angle change, and the emotion flips. Very economical. Very Japanese.”
But economy was a knife. The entertainment industry—geinōkai—had a gentle, smiling surface over iron rules. Contracts had clauses about dating, weight, and “public dignity.” The fanbase, mostly middle-aged men called oshi-men, demanded purity as if she were a miko (shrine maiden) selling charms instead of a woman singing about heartbreak. The pressure was a low, constant hum, like the 50-hertz electricity that powered the neon Tokyo skyline.
One autumn, the hum became a scream. A rival agency leaked a grainy photo of Airi leaving a ramen shop with a male actor. They weren’t holding hands; he was simply returning her umbrella. But the internet erupted. Betrayal. Rotton fruit. Within hours, her social media was a landfill of curses. Mr. Takeda called her to his glass-walled office overlooking Shibuya Scramble.
“You will apologize,” he said, not looking up from his tablet. “On the live stream. Kneel on the cushion. Wear a plain white blouse. Cry a little, but not too much. And you will say, ‘I have caused trouble for everyone.’”
“But I did nothing wrong,” Airi whispered. The phrase "Japanese entertainment industry and culture" is
Takeda finally looked at her. “Of course not. That’s not the point. The point is the ritual. The apology as performance. It’s the oldest story in our culture: the impurity must be cleansed. You bow, they forgive, we move on. That’s wa—harmony.”
He was right about the story. It was the same script used by politicians caught in scandals, sumo wrestlers who broke rules, and even the emperor’s family in a quieter century. Apologize. Absorb the shame. Disappear for a while. Return as if reborn.
That night, alone in her six-tatami-mat apartment, Airi didn’t cry. She went to her kamidana—the small household shrine her grandmother had insisted she bring. She lit a stick of sandalwood incense. The smoke rose straight, then wavered.
She remembered a legend her grandmother told: The camellia flower does not wilt petal by petal like a rose. It falls all at once, whole and still beautiful, decapitated by its own stem. That is a samurai’s death—clean, intentional, leaving no mess for others.
The next morning, the live stream began. Two million viewers tuned in. Airi knelt on a white cushion, her plain blouse crisp. The studio lights were hot as a summer festival. She bowed her head until it touched the floor—a saikeirei, the deepest bow of abject apology.
But when she raised her head, her face was not sad. It was serene. She did not cry.
She spoke not to the fans, but to the camera lens as if it were her grandmother’s eyes.
“I am sorry,” she said, “for the trouble. But I am not sorry for eating ramen. I am not sorry for having a friend. The only impurity here is the belief that a woman’s silence belongs to strangers.”
The studio staff froze. Mr. Takeda’s face, off-camera, went pale.
Airi smiled—that small, enigmatic smile—and stood up. She unpinned the Stardust Shoujo badge from her chest, placed it neatly on the cushion, and walked off the set. The live stream kept running. Two million people watched an empty cushion for forty-seven seconds before the producer cut the feed.
The industry declared her dead. Agencies blacklisted her. Her bandmates were told never to speak her name. But a few weeks later, a small video appeared on a niche platform. Airi, in plain clothes, sweeping the steps of her grandmother’s shrine in Kamakura. No makeup. No script. Just the rustle of bamboo and the distant sound of a temple bell.
The video went viral—not because of scandal, but because of peace. People commented: She found the real ma. That’s the quietest rebellion I’ve ever seen.
In Japanese entertainment, the rule is always: bend, don’t break. But Airi had learned a deeper cultural truth from the camellia. Sometimes, to stay whole, you have to fall.
She never performed again. But every autumn, pilgrims come to the small shrine. They leave camellia flowers at the gate and ask the young shrine maiden for a blessing.
She gives them silence. And somehow, that is exactly what they came to hear.
Modern Japanese entertainment is a unique blend of centuries-old traditions and cutting-edge global exports. The industry is defined by its ability to balance "Cool Japan"—the high-tech, neon-lit world of anime and gaming—with deep-rooted social values like harmony (wa) and meticulous craftsmanship (monozukuri). The Evolution of Japanese Entertainment
Japan’s entertainment landscape has evolved from restricted, elite performances to a massive global powerhouse:
Traditional Arts: Historical forms like Kabuki and Noh theater were the foundation of Japanese performance, focusing on heritage, spirituality, and elaborate costuming.
Modern Media: Today, Japan boasts a massive industry revolving around manga (comics) and anime, which serve as the creative engine for films, merchandise, and video games.
Social Hangouts: Domestic culture is heavily influenced by communal entertainment, such as karaoke parlors, game centers, and traditional board games like shogi or go. Cultural Pillars in the Industry
The success of the Japanese entertainment sector is often attributed to core societal "P's": being Precise, Punctual, Patient, and Polite.
Social Harmony: Japan is a conformist society that values group consensus. This is reflected in the "idol" culture and collaborative production committees that dominate the music and film industries.
Artistic Appreciation: A fundamental theme in the culture is an innate enjoyment of artistic activities, which ensures a high level of domestic support for new creative ventures. Global Impact
From the worldwide obsession with Nintendo and PlayStation to the mainstreaming of anime through streaming platforms, Japan’s "soft power" has made its entertainment industry a central part of global pop culture. This intersection of technology and art continues to define Japan's image on the world stage, proving that its cultural exports are as significant as its economic ones. AI responses may include mistakes. Learn more
Japanese Culture and Traditions - Tea Ceremony Japan ... - MAIKOYA
As Japan faces a declining birthrate and an aging population, the entertainment industry is pivoting to digital preserves.
VTubers—digital avatars controlled by human motion capture—represent the ultimate evolution of the "idol" concept. Stars like Kizuna AI and Gawr Gura (from Hololive) generate millions in revenue from "super chats" and virtual concerts. Unlike human idols, VTubers never age, never get sick, and can be franchised infinitely. This is arguably the most innovative sector of Japanese entertainment today.
Furthermore, the industry is finally embracing international co-productions. The success of Shogun (a US-produced show but deeply Japanese in soul) has opened the floodgates. Japanese production committees, historically distrustful of foreign interference, are now actively seeking global partners to fund the expensive CGI required for live-action anime remakes.
In the age of cord-cutting, Japanese TV remains an unshakeable giant. The major networks—Nippon TV, TV Asahi, TBS, Fuji TV, and NHK (public broadcasting)—wield immense cultural power.
Variety Shows (バラエティ, Baraeti): These are not talent shows like America’s Got Talent. Japanese variety shows are high-energy, chaotic experiments. They feature:
The Morning Drama (Asadora) and Period Dramas (Taiga): NHK’s Asadora (15-minute morning serials) and Taiga dramas (year-long historical epics) are national events. When an Asadora airs, it can boost tourism to a specific rural prefecture by 200%. These shows reinforce traditional Japanese values (filial piety, community, resilience) while modernizing them for contemporary audiences. Kabuki : A classical form of Japanese theater
Most of the Coders' Manual is devoted to explaining how to make decisions about the tags. This is extremely valuable information if you decide to study the tags for scientific purposes, because the instructions provide insights into what the tags mean and how the annotators made decisions.
Utterance objects have methods for accessing the POS-tagged version of the utterance as a plain string, and as a list of (string, tag) tuples. In addition, optional parameters to the methods allow you to regularize the words and tags in various ways:
utt.pos() gives you the raw string of the POS version:
You can use utt.text_words() to break the raw text on whitespace. More interesting is utt.pos_words(), which does the same for the POS-tagged version, which is often simpler, in that it lacks disfluency markers and information about the nature of the turn.
The option wn_lemmatize=True runs the WordNet lemmatizer:
pos_lemmas() has the same options as pos_words() but it returns the (string, tag) tuples:
As far as I can tell, the alignment between the raw text and the POS tags is extremely reliable, with differences largely concerning elements that were not tagged (mostly disfluency markers and non-verbal elements).
Not all utterances have trees; only a subset of the Switchboard is fully parsed. Here's a quick count of the utterances with parsetrees:
There are 221616 utterances in all, so about 53% have trees.
The relationship between the utterances/POS and the trees is highly frought. There is no simple mapping from the original release of the corpus, or the POS version, to the trees. For the parsing, some utterances were merged together into single trees, others were split across trees, and the basic numbering was changed, often dramatically. I myself did the text–POS–tree alignments automatically (not by hand!) using a wide range of heuristic matching techniques. There are definitely lingering misalignments. (If you notice any, please send me the transcript and utterance number.)
In the example used just above, the utterance and its POS match the tree, with the non-matching material being just trace markers and disfluency tags:
Sometimes the utterance corresponds to a subtree of a given tree. In that case, utt.trees includes the entire tree, and it is important to restrict attention to the utterance's substructure when thinking about (counting elements of) the tree(s):
Here, one can imagine pulling out (FRAG (IN if) (RB not) (ADJP (JJR more))) to work with it separately from its containing tree. NLTK tree libraries have a subtrees() method that makes this easy:
The most challenging situation is where the utterance overlaps two trees, but does not correspond to either of them, or even to identifiable subtrees of them:
Here, there is no unique node that dominates right, ?, and the disfluency marker but excludes the rest of the utterance
Of course, the easiest tree structures to deal with are those that correspond exactly to the utterance itself. The Utterance method tree_is_perfect_match() allows you to pick out just those situations. It does this by heuristically matching the raw-text terminals with the leaves of the tree structure. The following function counts the number of such utterances:
The output of the above is 96370 (0.829738688708 percent). This suggests that, when studying the trees, we can limit attention to matching-tree subset. However, we should first look to make sure that the overall distribution of tags is the same for this subset; it is conceivable that a specific tag never gets its own tree and thus would appear less in this subset.
Figure PERCOMPARE compares the percentages in Table DAMSL with the percentages from the restricted subset that that have full-tree matches. The distributions looks largely the same, suggesting that work involving parsetrees can limit attention to the matching-tree subset. However, if an analysis focuses on a specific subset of the tags, then more careful comparison is advised. (For example, x (non-verbal) and ^g (tag-questions) seem to be quite different from this perspective: non-verbal utterances are typically not parsed at all, and tag-questions are often treated as their own dialogue act but merged with the preceding tree when parsed.)
exercise ROOTS, exercise POS, exercise TAGS
SAMPLE Pick a transcript at random and study it a bit, to get a sense for what the data are like. Some things you might informally assess:
META The following code skeleton loops through the transcripts, creating an opportunity to count pieces of meta-data at that level. Complete the code by counting two different pieces of meta-data. Submit both the code and its output as your answer.
Advanced extension: allow the user to supply a Transcript attribute as the argument to the function, and then use that attribute inside the loop, to compile its cont distribution.
ROOTS The following skeletal code loops through the utterances, creating an opportunity to counts utterance-level information.
POSThis question compares heavily edited newspaper text with naturalistic dialogue by looking at the distribution of POS tags in two such resources.
TAGS How are tag questions parsed? Choose one of the following two methods for addressing this:
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.