One framework for creating
powerful cross-platform games
One framework for creating
powerful cross-platform games
Meet the MonoGame team and get your questions answered
MonoGame Spotlight Announcement
Timescales and Releases
By leveraging C# and other .NET languages on Microsoft and Mono platforms you can write modern, fast, and reliable game code using your editor of choice.
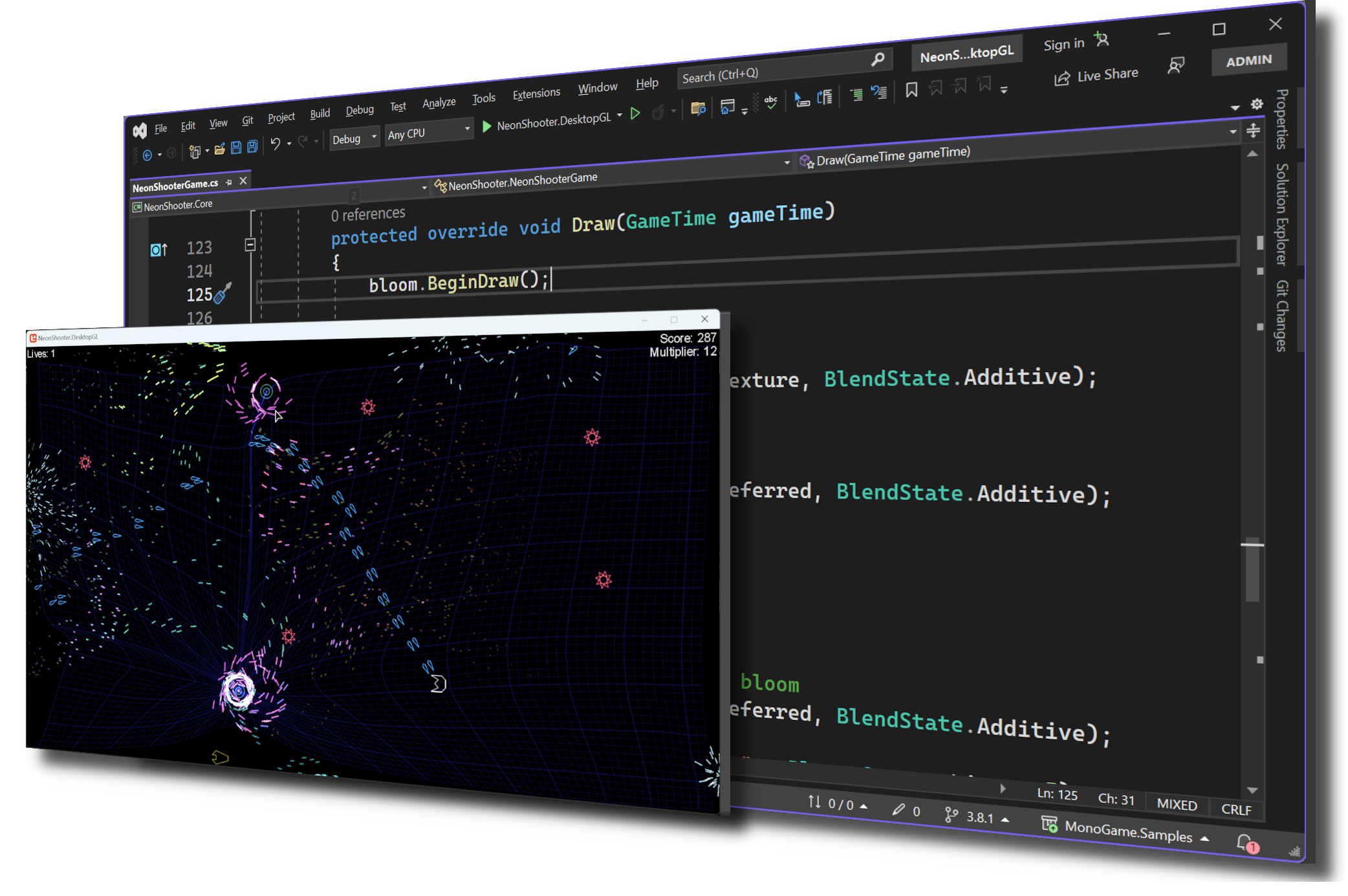
Build your game for multiple platforms. MonoGame currently supports:
* Console access requires you to be authorized for those platforms.
CID (Character Identifier) fonts are a mechanism originally developed by Adobe to support large, multi-byte character collections (notably CJK — Chinese, Japanese, Korean) in PostScript and PDF. CID fonts map CIDs to glyphs and are commonly used where thousands of characters must be addressed efficiently. The labels F1, F2, F3, F4 in many toolchains and documentation are informal identifiers for different CID font resources or font dictionaries rather than standardized type names; below is a concise guide explaining their meanings, differences, and practical implications.
Now, we reach the core of our keyword: "cid font f1 f2 f3 f4".
The letters F1, F2, F3, F4 are internal tags or font handles used by PDF creators (like Adobe Acrobat, InDesign, or PDFlib). They are not the actual name of the font (e.g., "SimHei" or "Kozuka Gothic Pro").
Why it happens: The PDF uses a custom CMap for F3 that doesn't map CIDs back to Unicode correctly. The visual glyph (what you see) is correct, but the internal text layer is code 0234 which your OS interprets as a Latin character.
Solution: Use OCR (Optical Character Recognition) via Adobe Acrobat’s "Enhance Scans" tool to rebuild the text layer over the existing CID glyphs.
To understand the depth of F1 through F4, one must understand what they represent in the PDF architecture.
In the realm of digital typography, particularly for complex scripts like Chinese, Japanese, and Korean (CJK), the limitations of traditional font formats such as Type 1 quickly became apparent. The need to handle thousands of glyphs efficiently led to the development of CID-keyed fonts (Character Identifier fonts). Within the technical documentation and internal structuring of these fonts, the designators F1, F2, F3, and F4 serve critical, distinct roles. These are not merely arbitrary labels but represent a logical hierarchy for processing character identifiers, mapping them to glyphs, and managing font resources. Understanding F1 through F4 is essential to grasping how modern CJK typesetting systems operate with speed and precision.
First, it is necessary to establish the foundational concept of a CID-keyed font. Unlike traditional fonts that rely on a single-byte encoding (e.g., ASCII for Latin fonts), a CID font separates the character collection from the glyph descriptions. A CID is a number that identifies a character, not its visual representation. A CMap (Character Map) then translates between an external encoding (like Shift-JIS or Unicode) and these internal CIDs. The "F" designators—F1 through F4—are specific data structures or processing states within the Adobe Type Manager and PostScript rendering engines that facilitate this mapping and glyph retrieval process. cid font f1 f2 f3 f4
F1 typically represents the font’s primary CIDFont resource. It acts as the central dictionary or container that holds the glyph descriptions (charstrings) indexed by their CID numbers. In essence, F1 is the core visual database. When a rendering engine receives a CID, it queries F1 to find the corresponding vector outline for that character. F1 also contains crucial metadata, such as the default metrics (widths, heights) and the supplement number, which indicates the version of the character collection. Without F1, the raw CIDs would have no visual form; it is the "glyph library."
F2 and F3 are more specialized, often functioning as subsidiary or composite dictionaries. In complex scripts, a single final glyph may be composed of multiple parts. For example, a CJK character might consist of a radical and a phonetic component, or a vertical writing variant may require rotated or shifted glyphs. F2 commonly stores composite character data—instructions on how to combine base glyphs (referenced via their CIDs in F1) to form a new, higher-level character. F3, in turn, might hold variation or stylistic alternates, such as different glyph forms for the same CID (e.g., traditional vs. simplified, or printing vs. handwriting style). By organizing this data across F2 and F3, the font achieves modularity and avoids redundant storage of similar glyph parts.
F4 often serves the most dynamic role: the CMap or processing context. Unlike the static dictionaries F1-F3, F4 represents the active mapping interface between an input encoding (like Unicode text) and the internal CIDs used by F1. In some technical descriptions, F4 is the "virtual font" or the composite font object that ties together multiple F1 resources (e.g., one for Japanese, one for Latin) and selects which F2/F3 rules apply based on the context (e.g., horizontal vs. vertical writing mode). It is through F4 that a text renderer decides which CID to request from F1 and how to instruct F2/F3 to modify that glyph.
In practical operation, the four functions work in a pipeline. When a document containing Japanese text is rendered:
The separation of duties among F1, F2, F3, and F4 confers immense advantages: efficiency (reusing common glyph parts), compactness (no need to store every CJK character as a unique, atomic glyph), extensibility (adding a new character collection only requires a new CMap, not a new glyph set), and flexibility (switching between horizontal and vertical writing or regional variants becomes a matter of changing the F4 context, not the entire font).
In conclusion, the designators F1 through F4 in CID-keyed fonts are not superficial technical labels but represent a sophisticated, layered architecture for multilingual typography. F1 acts as the glyph repository, F2 manages composition, F3 handles variations, and F4 orchestrates the mapping and context. Together, they solve the historic problem of representing thousands of complex characters without bloating file sizes or compromising rendering speed. For designers, engineers, and typographers working with East Asian languages, understanding this F1-F4 framework is not merely academic—it is essential to harnessing the full power of digital type. CID Fonts: F1, F2, F3, F4 — Overview
CID Font: CID (Character ID) fonts are a type of font used in PostScript and PDF documents. They are designed to efficiently handle large character sets, such as those for Asian languages, by mapping character IDs to glyph indices. CID fonts are crucial in typesetting for languages with large numbers of characters.
F1, F2, F3, F4: These could refer to different features or functions within a software application or hardware device. For example:
Given the combination of these terms, if you're asking about how to identify or work with a CID font that has been designated or referenced as "f1 f2 f3 f4", here are some informative points:
CID Fonts in PDFs: CID fonts are often embedded in PDF documents to ensure portability and accurate rendering across different systems. If you're dealing with PDFs, software like Adobe Acrobat can provide information about the fonts used, including CID fonts.
Font Mapping and Substitution: When working with documents that use specific fonts like CID fonts, font mapping or substitution might occur if the target system doesn't have the exact font. This could involve F1, F2, F3, and F4 referring to fallback or substitute fonts.
Identifying Fonts: If you're trying to identify or manage fonts like CID fonts within a document or system, you would typically look for font management tools or sections within the software you're using. For instance, in Adobe Creative Cloud applications, there's usually a panel or option for managing and substituting fonts. F1: CID font for Japanese Kanji/Kana (like Kozuka
Specific Software Commands or Parameters: If "cid font f1 f2 f3 f4" comes from a specific software command or parameter (like in LaTeX, a typesetting system; or within a script for a graphic design application), the documentation for that software would likely explain what each part means and how to use them.
To provide a more detailed or accurate response, I would need a more specific context or software application you're referring to.
In the quiet architecture of digital documentation, there exists a phenomenon that is simultaneously a glitch, an aesthetic, and a philosophical statement: The CID Font Hierarchy.
When you see the sequence F1, F2, F3, F4, you are not looking at a mistake. You are looking at the exposed skeleton of communication. You are seeing the ghost in the machine refusing to wear its skin.
Here is a deep dive into the quiet tragedy of the CID Font.
Overall Verdict:
This is not a specific font name but a technical reference pattern seen inside PDF files, related to how CID-keyed fonts are organized. For a typical user, it means nothing; for a developer or forensic analyst, it indicates a structured but generic font subset.
MonoGame is, and will always remain, free to use. There is no subscription model, royalty payments, licensing costs, or runtime fees associated with using MonoGame.
The MonoGame Foundation is a non-profit foundation that relies on community donations to fund its projects and goals. Consider supporting MonoGame through a one-time or monthly donation.